- Publication: OpenAI
- Publication Date: 3/4/2022
- Organizations mentioned: OpenAI
- Publication Authors: Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, Ryan Lowe
- Technical background required: High
- Estimated read time (original text): 49 minutes
- Sentiment score: 78%, somewhat positive
Goal:
Researchers at OpenAI developed a method called InstructGPT to align large language models (LLMs) with human intentions by fine-tuning them using human feedback. The goal was to create LLMs that are more helpful and honest while maintaining strong performance on natural language processing (NLP) tasks.
Methodology:
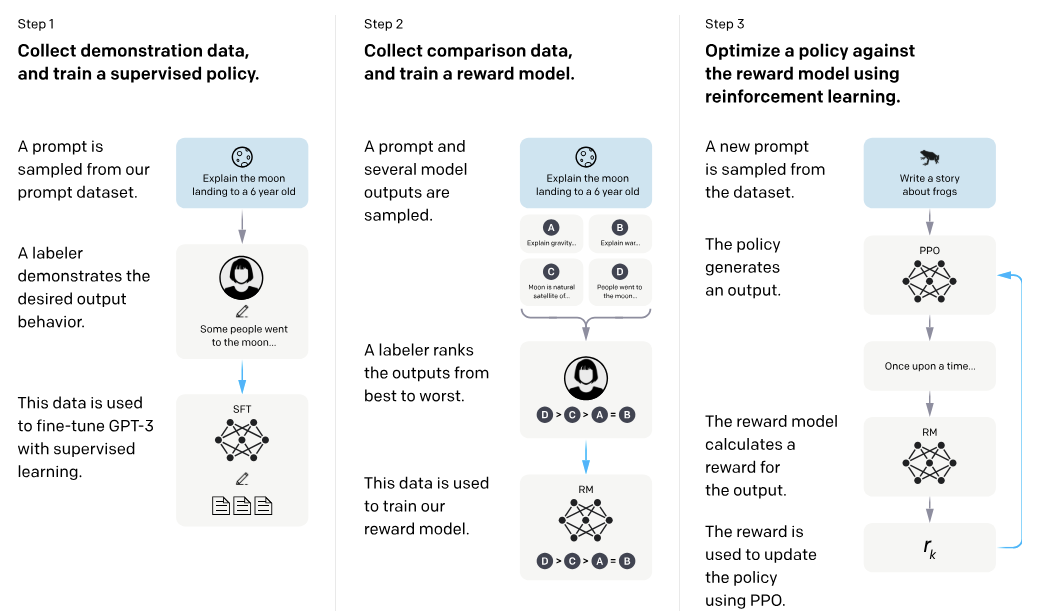
- Started with GPT-3, a pretrained LLM, and collected a dataset of human-written demonstrations of desired model behavior on prompts submitted through the OpenAI API.
- Fine-tuned GPT-3 using supervised learning on the demonstration dataset, then collected a dataset of human rankings comparing model outputs.
- Further fine-tuned the model using reinforcement learning based on the human ranking dataset to create InstructGPT models.
Key findings:
- Outputs from a 1.3 billion parameter InstructGPT model were preferred by humans over outputs from the 175B parameter GPT-3 model, despite being over 100 times smaller.
- InstructGPT models generated truthful and informative answers on the TruthfulQA benchmark about twice as often as GPT-3. They also “hallucinated” (made up facts) about half as often as GPT-3 on closed-domain tasks like summarization.
- By mixing in pretraining data during reinforcement learning, InstructGPT maintained strong performance on standard NLP benchmarks like SQuAD, minimizing the “alignment tax” (performance loss from aligning AI systems with human preferences).
- Public NLP datasets do not fully capture the distribution of tasks users want to accomplish with LLMs. InstructGPT outperformed models fine-tuned on the FLAN and T0 datasets, which consist of diverse NLP tasks with instructions.
- InstructGPT showed promising generalization to instructions outside its training distribution, such as non-English languages and coding tasks, suggesting it learned a general concept of “following instructions.”
Recommendations:
- The InstructGPT approach is a promising avenue for aligning AI systems with human intentions as they become more capable. Incorporating human feedback enables faster adaptation compared to specifying all desired behaviors in advance.
- As LLMs become more powerful, human oversight will likely be crucial to ensure their outputs remain safe, truthful, and beneficial. Challenges around defining and implementing the “right” behaviors will grow, requiring public discourse and policy frameworks.
- Further research is needed to improve and scale techniques like InstructGPT. Potential future directions include using adversarial data collection to reduce remaining failure modes and exploring more efficient forms of human feedback beyond binary comparisons.
Implications:
- As AI language models become more powerful and widely deployed, aligning their behavior with human values will be critical to ensure they are beneficial and trustworthy. If organizations don’t adopt techniques like InstructGPT, we may face increased risks of AI systems generating harmful, biased, or misleading content, eroding public trust and limiting their positive impact.
- The success of InstructGPT in improving language model behavior through human feedback suggests this approach could be applied to other domains where AI systems interact with humans, such as computer vision, robotics, and decision support systems. This could lead to a proliferation of AI assistants and tools that are more user-friendly, culturally aware, and adaptable to individual preferences.
- The challenges highlighted in the InstructGPT research, such as defining and aggregating diverse human preferences, underscore the need for inclusive public discourse and policy frameworks around the development and deployment of AI systems.
Alternative perspectives:
- While InstructGPT demonstrates the potential of human feedback to align AI systems, the approach may not scale effectively to more advanced AI systems or complex domains where human evaluation is difficult or costly. Developing scalable and robust alignment techniques, such as value learning or debate, may be necessary to ensure AI remains beneficial as it becomes more autonomous and capable.
- The focus on aligning AI with human preferences raises questions about whose preferences should be prioritized and how to handle conflicts between individuals or groups. There is a risk that alignment techniques like InstructGPT could perpetuate or amplify existing biases and power imbalances if not designed and implemented with care.
- The InstructGPT research emphasizes the importance of human feedback, but it may underestimate the potential of other approaches, such as improved pretraining, fine-tuning on carefully curated datasets, or incorporating explicit ethical constraints into AI systems. A combination of techniques may be necessary to ensure AI alignment across a wide range of applications and contexts.
AI predictions:
As techniques like InstructGPT mature and become more widely adopted, we can expect to see a growing number of AI assistants and chatbots that are more helpful, informative, and culturally sensitive. This could lead to increased productivity and user satisfaction in domains such as customer service, education, and personal assistance.
The success of human feedback in aligning language models may accelerate research into applying similar techniques to other AI domains, such as computer vision and robotics. We may see the development of AI systems that can learn from human demonstrations and preferences to perform physical tasks or assist with decision-making in fields like healthcare and finance.
The challenges of aligning AI with human values, as highlighted by the InstructGPT research, may spur increased collaboration between AI researchers, social scientists, policymakers, and the public to develop governance frameworks and best practices for responsible AI development. This could include the establishment of international standards, ethical guidelines, and mechanisms for public participation in shaping the future of AI
Glossary
- InstructGPT: A method developed by OpenAI researchers to align language models with human intentions by fine-tuning them using human feedback.
- Alignment tax: The performance loss that may occur when aligning AI systems with human preferences, as measured on standard NLP benchmarks.
- Hallucination: When a language model generates or “makes up” facts that are not present in the input or context.
- TruthfulQA: A benchmark dataset used to evaluate the truthfulness and informativeness of language model outputs.
- Winogender and CrowS-Pairs: Datasets used to measure social bias in language model outputs.
- FLAN and T0: Datasets consisting of diverse NLP tasks with instructions, used to compare InstructGPT’s performance to models fine-tuned on a wide range of tasks.
No hype. No doom. Just actionable resources and strategies to accelerate your success in the age of AI.
 Join hosts Anthony, Shane, and Francesca for essential insights on AI's impact on jobs, careers, and business. Stay ahead of the curve – listen now!
Join hosts Anthony, Shane, and Francesca for essential insights on AI's impact on jobs, careers, and business. Stay ahead of the curve – listen now!
Recommended Research Reports


No hype. No doom. Just actionable resources and strategies to accelerate your success in the age of AI.
Join hosts Anthony, Shane, and Francesca for essential insights on AI's impact on jobs, careers, and business. Stay ahead of the curve – listen now!
All Signal.
No Noise.
One concise email a day. Curated by Anthony Batt & Harry DeMott.
Free. Unsubscribe anytime.